Data Engineering
Cloud
Analytics
Big Data
The Modern Data Engineering Stack: Building Reliable Data Pipelines in 2026
Rocambys Team28 March 20263 min read
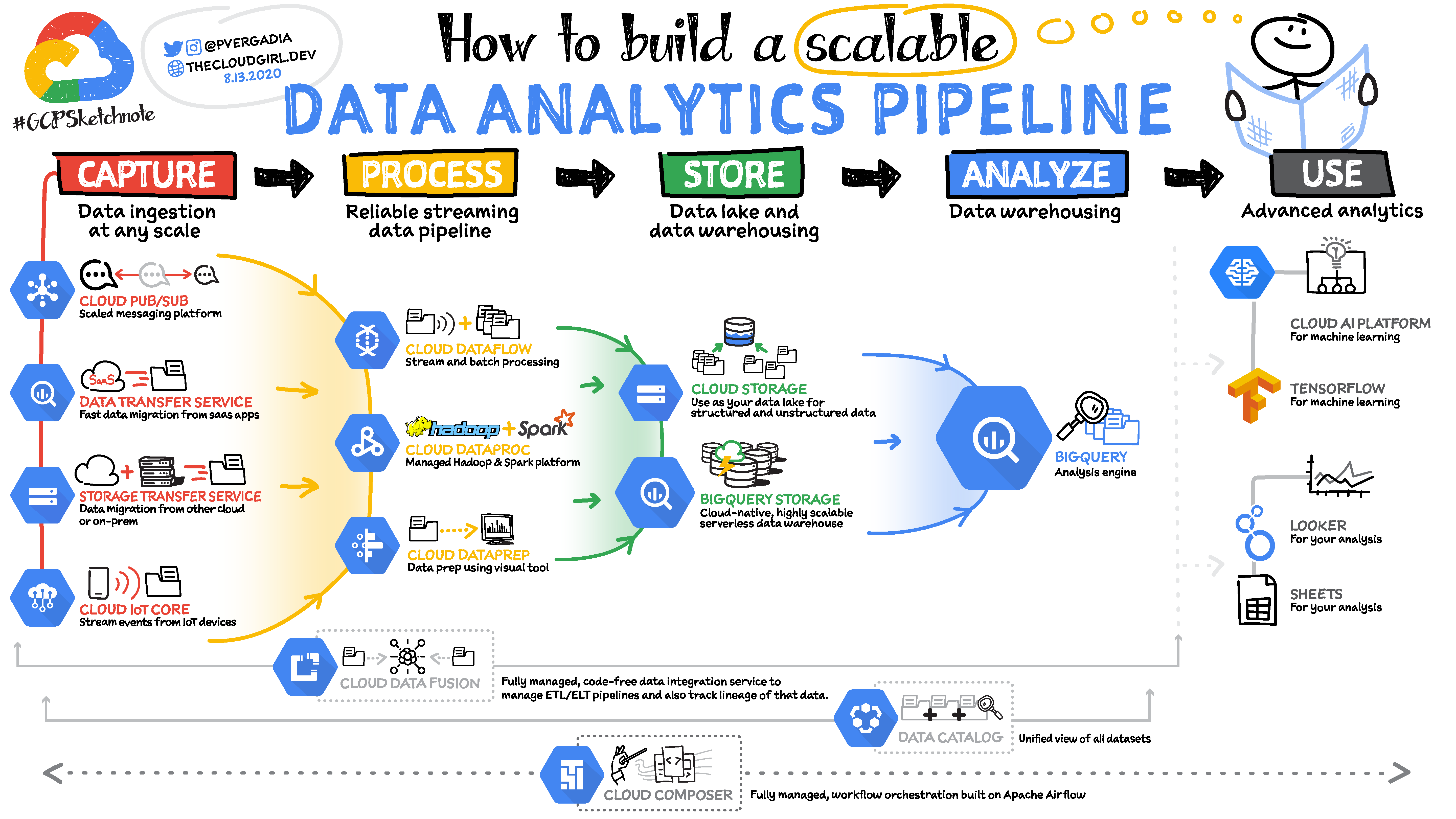
The Evolution of Data Engineering
Five years ago, data engineering meant managing Hadoop clusters and writing Spark jobs. Today, the landscape has shifted toward managed services, real-time streaming, and data mesh principles. The core challenge remains the same: getting the right data to the right people at the right time, reliably.
The Reference Architecture
A modern data platform typically consists of five layers:
1. Ingestion Layer
- Batch — Airbyte, Fivetran, or custom connectors for database replication and API extraction.
- Streaming — Apache Kafka (or Amazon MSK) for real-time event ingestion.
- CDC — Debezium for change data capture from operational databases.
2. Storage Layer
- Data lake — Amazon S3 or Google Cloud Storage as the foundation.
- Table format — Apache Iceberg (preferred), Delta Lake, or Apache Hudi for ACID transactions on the lake.
- Catalog — AWS Glue Data Catalog or Apache Polaris for metadata management.
3. Transformation Layer
- dbt — The standard for SQL-based transformations with testing and documentation.
- Spark — For complex transformations that exceed SQL capabilities.
- Data quality — Great Expectations or Soda for data validation at every stage.
4. Serving Layer
- OLAP — Amazon Redshift, Snowflake, or BigQuery for analytical queries.
- Real-time — Apache Druid or ClickHouse for sub-second dashboards.
- Feature store — Feast or Tecton for serving ML features.
5. Orchestration Layer
- Apache Airflow (MWAA) or Dagster for workflow orchestration.
- Data lineage — OpenLineage for tracking data provenance across the entire stack.
Key Principles
- Idempotency — Every pipeline should be safely re-runnable without duplicating data.
- Schema evolution — Design for change. Use schema registries and backward-compatible formats.
- Data contracts — Define explicit contracts between producers and consumers.
- Cost awareness — Monitor per-query and per-pipeline costs. Data platforms can become the largest cloud expense.
Conclusion
The modern data engineering stack is more capable and more complex than ever. Success depends on choosing the right tools for your scale, investing in data quality from the start, and treating your data platform as a product with dedicated engineering resources.