Kubernetes in Production: 10 Lessons Learned from Enterprise Deployments
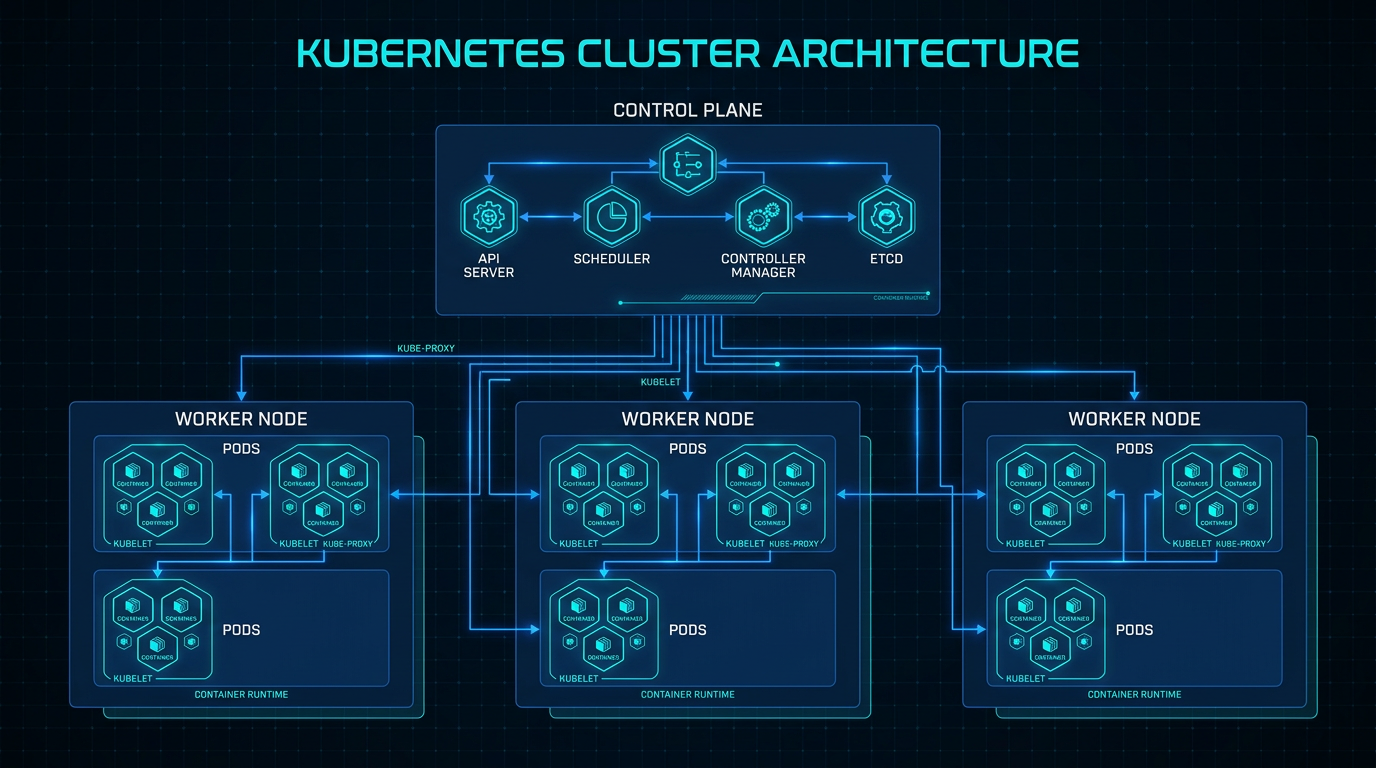
Kubernetes Is Not a Silver Bullet
Every enterprise wants Kubernetes. Few are prepared for the operational complexity it introduces. After managing Kubernetes clusters for organizations across finance, healthcare, and technology, we have distilled the most critical lessons.
Lesson 1: Start with Managed Kubernetes
Unless you have a dedicated platform team of 5+ engineers, do not self-manage Kubernetes. Use EKS, GKE, or AKS. The control plane is not where your competitive advantage lies.
Lesson 2: Namespace Strategy Matters
Design your namespace structure before deploying a single workload. We recommend: one namespace per team or service domain, with resource quotas and network policies from day one.
Lesson 3: Resource Requests and Limits Are Non-Negotiable
Every container must have CPU and memory requests and limits defined. Without them, a single misbehaving pod can bring down an entire node. Use Vertical Pod Autoscaler (VPA) to establish baselines.
Lesson 4: Invest in Observability Early
Deploy Prometheus, Grafana, and a log aggregation stack (Loki or ELK) before your first production workload. Retrofitting observability is ten times harder than building it in from the start.
Lesson 5: GitOps Is the Only Sane Deployment Model
Use ArgoCD or Flux to manage deployments declaratively. No manual kubectl applies in production, ever. Git becomes your single source of truth.
Lesson 6: Network Policies Are Your Internal Firewall
By default, every pod can communicate with every other pod. Implement deny-all default policies and explicitly allow only required traffic paths. Use Calico or Cilium for enforcement.
Lesson 7: Secrets Management Requires a Dedicated Solution
Kubernetes Secrets are base64-encoded, not encrypted. Integrate with HashiCorp Vault, AWS Secrets Manager, or Sealed Secrets for production-grade secrets management.
Lesson 8: Plan for Cluster Upgrades from Day One
Kubernetes releases a new minor version every 4 months. Upgrades are mandatory (n-2 support policy). Build upgrade runbooks and test them in staging regularly. Blue-green cluster upgrades are safest for mission-critical workloads.
Lesson 9: Pod Disruption Budgets Prevent Outages
Define PodDisruptionBudgets for every production deployment. Without them, node drains during upgrades can take down entire services.
Lesson 10: Cost Visibility Is Essential
Kubernetes makes it easy to overspend. Use tools like Kubecost or OpenCost to track spending per namespace, team, and workload. Implement cluster autoscaler with appropriate scale-down policies.
Final Thought
Kubernetes is an exceptional platform when operated correctly. The difference between success and failure is not the technology — it is the operational maturity of the team running it.